Why we linked text instead of scraping data for 'Who is my neta?
October 20, 2024
Earlier in 2024, I helped make whoismyneta.com just before the Indian general elections, and it went a little viral, but an unexpected restriction was about to make the site useless at the very peak of its usefulness (and popularity). Though I say so myself, I think what we ended up doing to overcome it was quite clever.
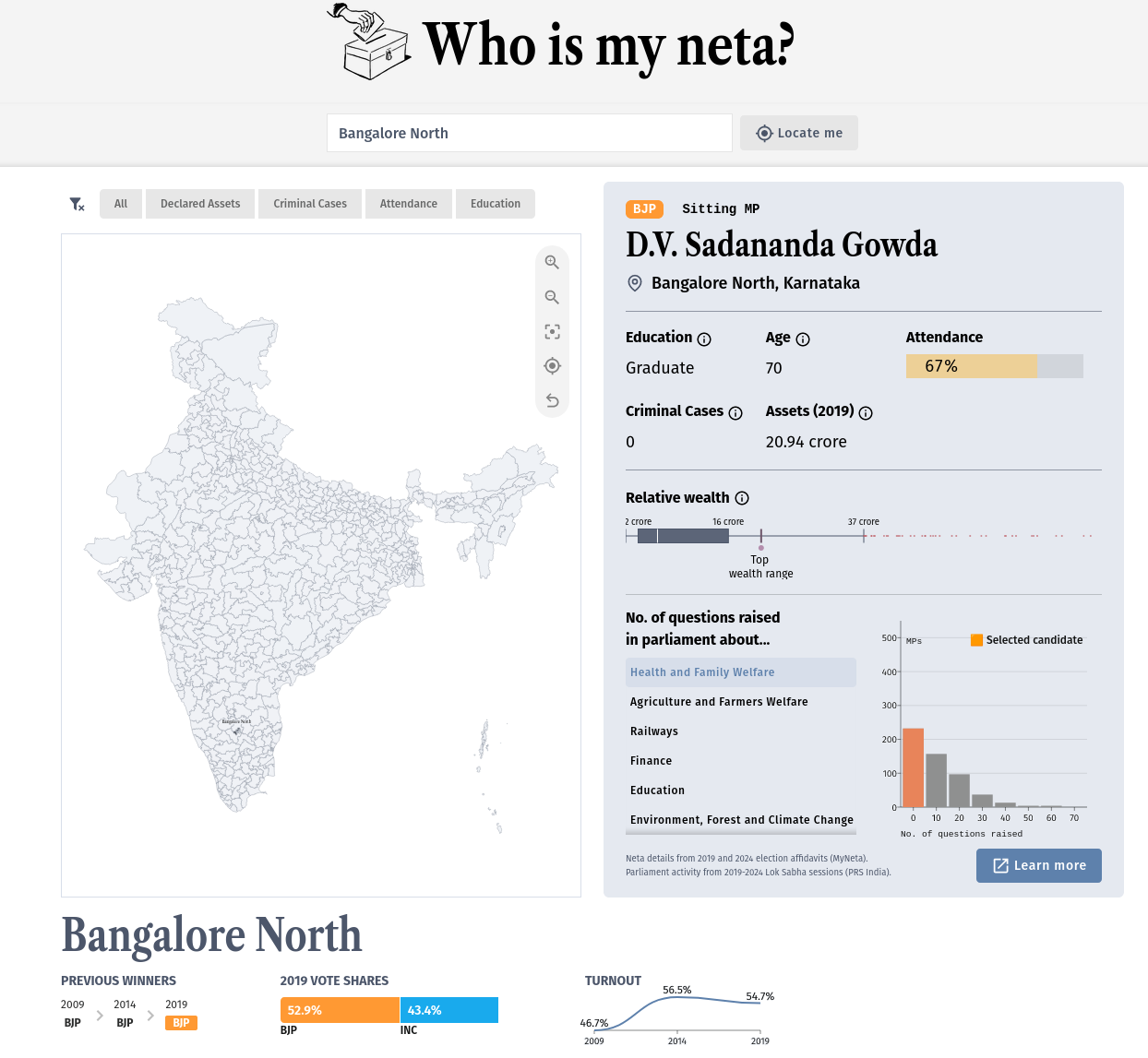
Some background on Who Is My Neta
In April, Opencity.in organized an online datajam around the theme of the 17th Lok Sabha elections, which I took part in along with my teammates Vivek and Pravar.
Vivek had already been collating data on legislative activity of parliament members as well as data from MyNeta.info run by the Association for Democratic Reforms (ADR). Their data is makes is assembled through candidate-submitted affidavits which contain information such as criminal cases, education level, and declared assets. This was data on the current MPs on their way out. He had the novel idea of joining these two datasets and creating a single explorer for them. It sounded great to me.
For context, this project almost feels like a rite of passage for people interested in open data, politics, and building visualizations. By no means had the ADR data not been visualized before; here are just some projects that have done similar things:
- https://www.reuters.com/graphics/INDIA-ELECTION-CRIMINAL-CANDIDATES/0100925031T/
- https://github.com/datameet/india-election-data/tree/master/affidavits
- https://github.com/nini1294/myneta_api
- https://github.com/bkamapantula/parliamentary-candidates-affidavit-data
- https://github.com/kracekumar/myneta
- https://github.com/manish-tcpd/myneta
And so on. You get the idea. People find this data useful, they also like to make stuff with it.
What we were doing was different because of the join that Vivek had in mind (along with some better UI/UX decisions on how to make accessing this easy on the web interface). In a single place, you could see information that ADR had while also seeing how the parliamentarian had engaged with questions and debates in their term. We also had loftier ideas of more interesting stats like identifying turncoat candidates, but maybe that’s for another day.
Long story short, we built it (and I’ll write about that in a future post). I shared it. It went viral. Even though the data was not yet for the candidates contesting this year, people found it useful and shared the site widely. It spawned reels, videos, explainers on how to use it, and people sharing screenshots of their MPs, completely organically. A few days after the initial hullabaloo, I set up a Plausible instance to track (I’m usually very anti-analytics, but this was new, and I wanted to see what the numbers were this once) how many visits we were getting.
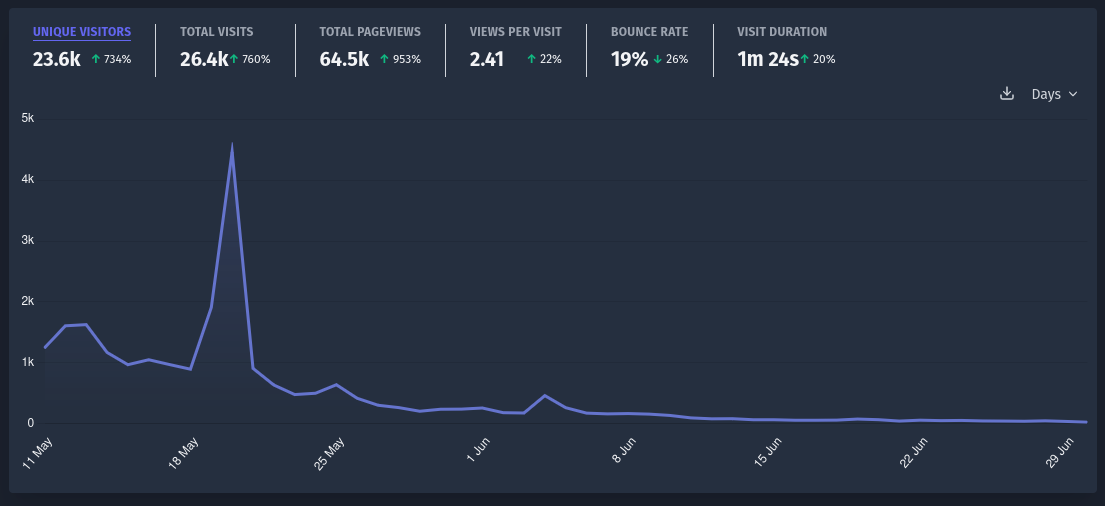
That spike was after the surge of the first week, so the number of unique visitors would easily be 1.5–2 times more.
All this to say, it had plenty of eyeballs on it, and we kept getting requests to update this with data for the candidates who would be contesting this year. Of course that would be useful, right?
You shall not scrape

To make sure that we were not doing something unwanted, we reached out to the open-data platform we had earlier scraped from and asked if this would be okay with them. We had made sure to appropriately credit the data to them to begin with, but having formal permission would have been nicer.
After a meeting with them, it was decided that they didn’t want us to scrape any more data. While it is obviously their right to deny us this permission, it was certainly a disappointment for us. The platform we had built was making it easier for people (even if a seemingly small amount) to take an interest in this information, but our data would remain outdated.
Thinking of alternatives
Since the cleaned data by ADR’s open-data platform was not available for use by anyone else, we began to think of alternate ways to keep our dashboard updated with the similar data for this year’s candidates. The first thing to consider was assembling this data on our own. But have a look at how it can be filed:
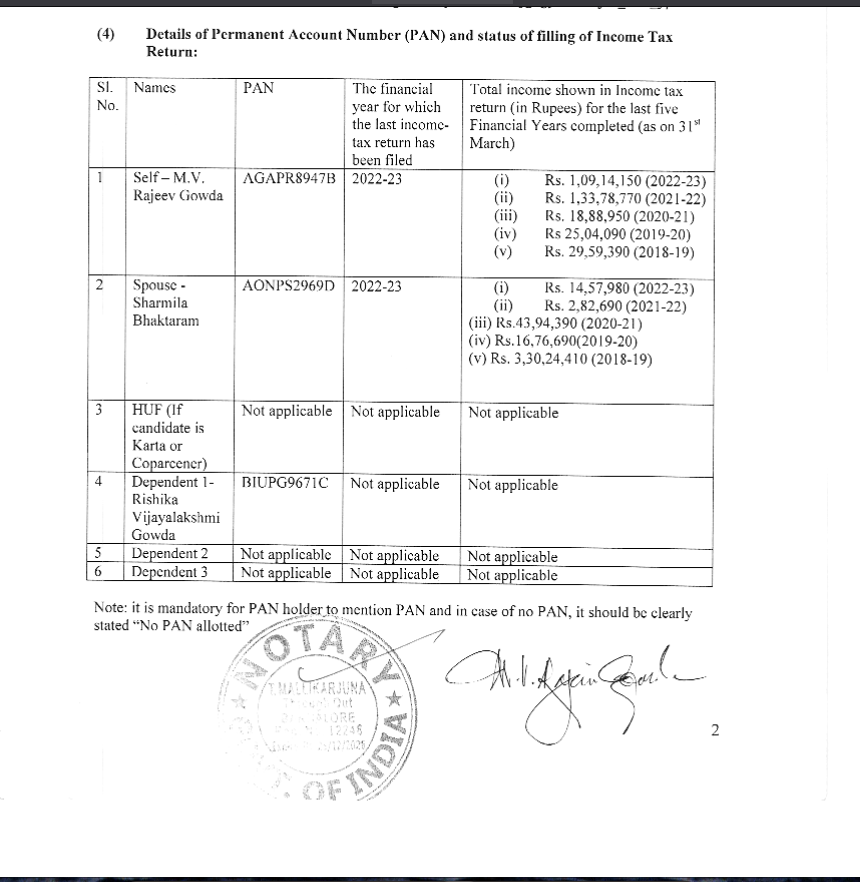
The data does not come in a neat key-value pair format, but tables after tables of individual things. Even if you manage to crack the format of the form for one state, what about when this happens: 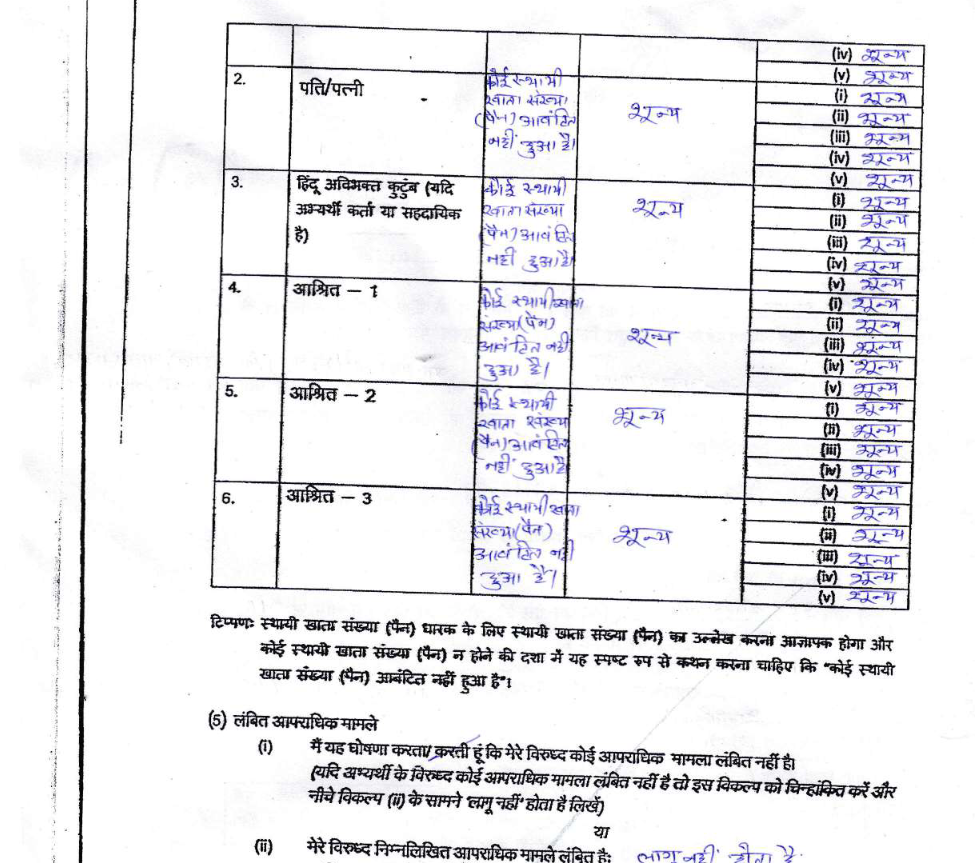
English, Hindi, handwritten, typed, skewed, rotated—there is no one way that the affidavits come in. Cleaning it is hard work, and to that end, I could possibly see why the folks who cleaned this want the data only on their platform (how that platform might hinder easy access for the casual user is another matter). OCR was out of the question. And there was no other format this data came in. MyNeta.info is all there was.
Enter Text Fragments
Here’s what we did have:
- Names of candidates, since we only needed the official Election Commission of India website for that.
- We knew the URL structure of the pages where the other folks listed candidates for each constituency.
We could also collect the exact URLs for each candidate’s page on ADR’s site, but that would involve automated scraping, and we would rather not get into that again. No, thank you.
Our initial thought was to just list out candidates contesting in a certain constituency this year and link to that page on My Neta. It was a very lousy solution because the candidates there are listed in a table, which can often get very long. If I already knew what candidate I wanted to read about, then there was an extra step of searching the whole table for that person.
What if we could link directly to the candidate on that table? That would be…neat. Text Fragments feature lets you do exactly that. Select a piece of text on the page, right-click, and select ‘Copy link to highlight,’ and it builds a URL that takes the reader right to that piece of text, already highlighted. That’s very cool. Instead of linking to pages, we could link to positions on pages. I could link you to this Monty Python sketch.
The URL is already easy to build:
http://example.com#:~:text=Text%20%27to%27%20highlight%%3F #:~:text= will ask the browser to look for the first piece of text that matches the parameter on the page. This was extremely useful! Now instead of just linking to the page, we could scroll to and highlight the candidate you were interested in. Here’s how it looks on the MyNeta website:
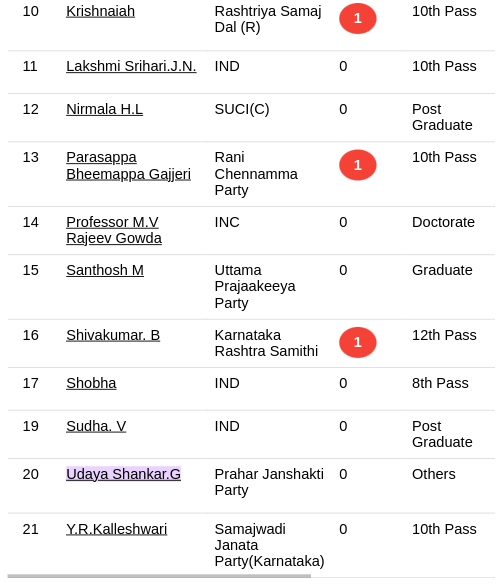
Awesome! In our code, this is how we constructed URLs for each candidate:
function formatTextForHighlight(text) { return '#:~:text=' + encodeURIComponent(text);}let link = `https://www.myneta.info/LokSabha2024/index.php?action=show_candidates&constituency_id=${constituencyID}${formatTextForHighlight(candidate.candidate_name)}`; This works on a couple of assumptions:
- Each candidate has a unique name or, at the very least, their name is spelled a specific way. If there are two ‘Shobha’s on the page, then only the first one is highlighted. In most cases, this does not happen.
- People use a supported browser. As of writing this, text fragments are available in Chrome and Firefox If the numbers are anything to go by, this is a fairly okay assumption to make.
But if you’re using a browser that does not have this feature, then we let you know in the popup that opens the first time you try going to a candidate:
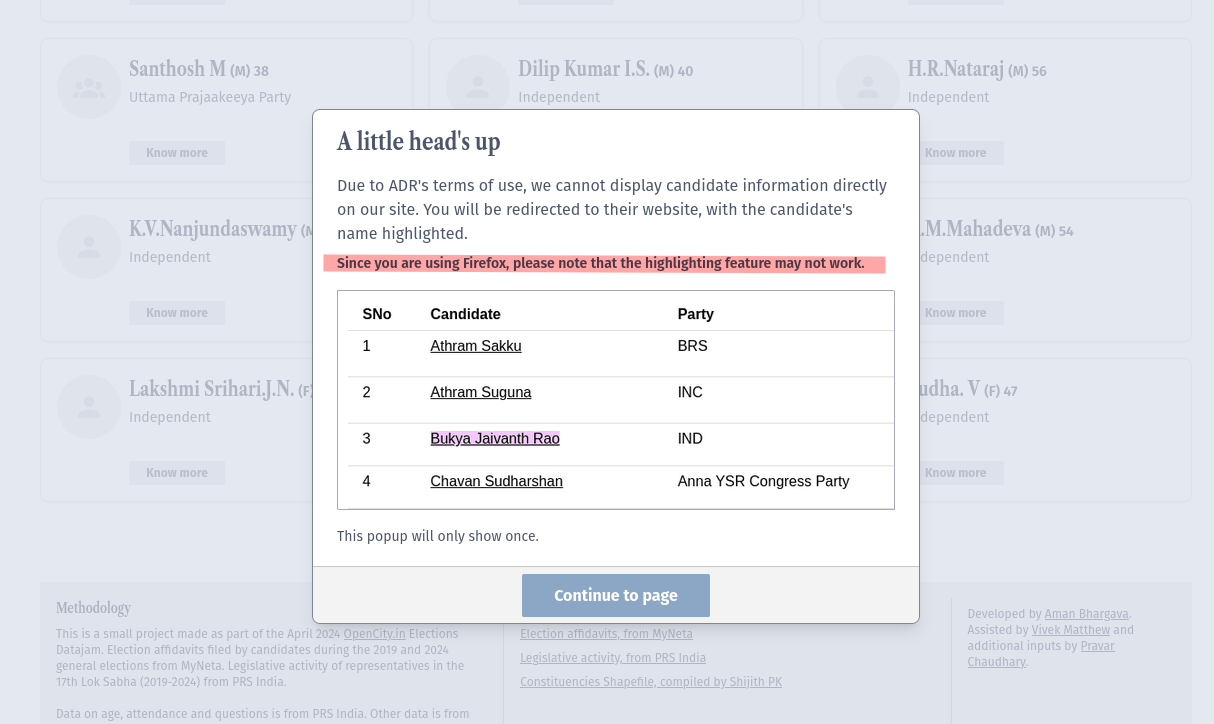
Note: When we launched our dashboard, this feature was not available in Firefox. It has now made it into the latest version of Firefox! The browser allows you to open text fragment links but not create them (for now).
Instead of scraping data from the MyNeta website, we make a best-effort attempt to take you directly to what you want to see, instead of having to navigate dense tables and pages that you’d otherwise have to do. It (mostly) works.
Final thoughts
When I wrote the URL-building logic and saw it work, I was incredibly excited. It’s a stupid, stupid hack but it works. And making stuff like that is what makes all of this fun. Obviously, I would much rather show things in one place and not have to do this, but oh well, ¯\_(ツ)_/¯
Maybe the next group of programmers who go through this rite of passage will be the ones to do it and convince open-data folks to let them use the data.
I think the feature itself is very useful, and I hope it makes it fully into Firefox soon, it is close. It is also, by its very nature, very delicate; if the text on the page changes, then the highlight is broken (but the link gracefully degrades to a normal link). But in cases like these, it’s alright.
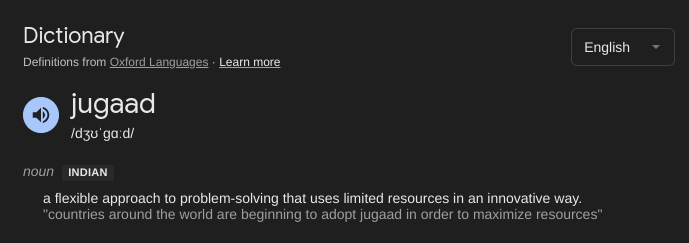
And now you know what jugaad means.